参考书目:《Tensorflow实战》
CS231n与CIFAR-10介绍
CS231n是Stanford开设的一门公开课,b站上直接就能看视频:https://www.bilibili.com/video/av13260183?from=search&seid=14626448354817426246,当然,看视频可能还是会感觉一头雾水,所以我推荐看cs231n给出的一个页面里的内容:http://cs231n.github.io/convolutional-networks/,这里他完整的介绍了原理,介绍了效果,总之很全。
什么?看不太懂?那就来看我的博客呀2333(逃~
下面我会用到很多从上面那个页面里的图。
CIFAR-10是一个数据集,有60000张32*32的彩图,训练集50000张,测试集10000张,有十个类别,都是:airplane、automobile、bird、cat、deer、dog、frog、horse、ship和truck。
唔,要注意这个东西,在tensorflow.examples.tutorials里并没有,所以我们得自己导入这个集合。
所以首先,我们要进入tf官方给的引导文件,然后引导下载和使用这个集合:
打开终端:
$ git clone https://github.com/tensorflow/models.git
$ cd models/tutorials/image/cifar10
或者你要是嫌麻烦,上面下载太慢,那么就不要运行上面两个了(毕竟咱们这里只需要用到cifar10),我这里已经给你准备好了两个py文件,你把它们下载一下,然后再进行后续操作,后续操作这两个py文件都得带着:
然后新建一个py文件,在前面写上:
import cifar10, cifar10_input
import tensorflow as tf
import numpy as np
import time
max_steps = 3000
batch_size = 128
data_dir = '/tmp/cifar10_data/cifar-10-batches-bin'
# Download and Extract
cifar10.maybe_download_and_extract()
images_train, labels_train = cifar10_input.distorted_inputs(data_dir, batch_size=batch_size)
images_test, labels_test = cifar10_input.inputs(eval_data=True, data_dir=data_dir, batch_size=batch_size)
然后运行一下吧,就可以看到下载和解压这个数据集合了,他很贴心的都给你分好了batch:
然后创建训练和标签的输入口:
image_holder = tf.placeholder(tf.float32, [batch_size, 24, 24, 3])
label_holder = tf.placeholder(tf.int32, [batch_size])
那么,为什么输入口这里是24243,而不是32323呢?因为在上面加载数据的时候,剪裁了图片正中间的2424的区块。为什么要这么做,这其实是【数据增强】的一部分,查看cifar10_input.distorted_inputs函数,会发现将原图进行了水平翻转(tf.image.random_flip_left_right),剪裁中间2424(tf.random_crop),设置随机亮度和对比度(tf.image_random_brightness, tf.image.random_contrast),对数据标准化(tf.image.per_image_whitening)这一大堆操作,都是为了【得到更多的样本!提升准确率!】,也就是一图变多图,考虑进一个图在不同状态下的表现,这样识别起来更准确。
网络结构
下面可以定义网络结构了。
首先和上一篇一样,要得到一个初始化weight的函数,但是和上一篇不一样的是,这里我们加一个L2的正则,为什么?防止过拟合。
为什么L2正则能降低过拟合呢?现在我们使用某一个特征时,会付出loss的代价,除非这个特征,它不一样,能起到很强的效果,才能够把loss上的增加给覆盖掉。这样一些无关紧要的特征就覆盖不到loss,网络自然检测不到。
def variable_with_weight_loss(shape, stddev, wl):
var = tf.Variable(tf.truncated_normal(shape, stddev=stddev))
if wl is not None:
weight_loss = tf.multiply(tf.nn.l2_loss(var), wl, name='weight_loss')
tf.add_to_collection('losses', weight_loss)
return var
然后定义第一层的结构:
# 5*5*3的卷积核,64个,第一个卷积层不正则
weight1 = variable_with_weight_loss(shape=[5, 5, 3, 64], stddev=5e-2, wl=0.0)
# 卷积运算
kernel1 = tf.nn.conv2d(image_holder, weight1, [1, 1, 1, 1], padding="SAME")
# bias
bias1 = tf.Variable(tf.constant(0.0, shape=[64]))
# 第一层的表达式
conv1 = tf.nn.relu(tf.nn.bias_add(kernel1, bias1))
# 尺寸3*3,步长2*2最大池化进行池化,尺寸和步数不一样,增加数据丰富性
pool1 = tf.nn.max_pool(conv1, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1], padding="SAME")
# LRN对活跃的特征放大,不活跃的进行移植,增加模型泛化能力
norm1 = tf.nn.lrn(pool1, 4, bias=1.0, alpha=0.001/9.0, beta=0.75)
要注意的是,LRN这个东西,全名叫Local Response Normalization,译名叫局部响应归一化,AlexNet在ImageNet的数据集上将它发扬光大,它会从响应的几个卷积核(也就是提取出来的特征)中,加强几个大的反馈,减弱几个小的反馈。另外ReLU不会梯度消失,能缓解过拟合,用在卷积层。SoftMax用在全连接。
然后定义第二层:
# 上一步提取了64个特征,现在输入5*5*64,不需要l2正则
weight2 = variable_with_weight_loss(shape=[5, 5, 64, 64], stddev=5e-2, wl=0.0)
kernel2 = tf.nn.conv2d(norm1, weight2, [1, 1, 1, 1], padding="SAME")
bias2 = tf.Variable(tf.constant(0.1, shape=[64]))
conv2 = tf.nn.relu(tf.nn.bias_add(kernel2, bias2))
norm2 = tf.nn.lrn(conv2, bias=1.0, alpha= 0.001/9.0, beta=0.75)
pool2 = tf.nn.max_pool(norm2, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1], padding='SAME')
然后准备输出了,构建第一个全连接层,隐藏节点数量设置384:
# 这里要对pool2进行拉长成一个向量
reshape = tf.reshape(pool2, [batch_size, -1])
dim = reshape.get_shape()[1].value
# 全连接层特别容易过拟合!一定要加l2正则
weight3 = variable_with_weight_loss(shape=[dim,384], stddev=0.04, wl=0.004)
bias3 = tf.Variable(tf.constant(0.1, shape=[384]))
local3 = tf.nn.relu(tf.matmul(reshape, weight3) + bias3)
然后再来一个一模一样的全连接层,隐藏层节点少一半:
weight4 = variable_with_weight_loss(shape=[384, 192], stddev=0.04, wl=0.004)
bias4 = tf.Variable(tf.constant(0.1, shape=[192]))
local4 = tf.nn.relu(tf.matmul(local3, weight4) + bias4)
最后一层输出,把192个隐藏节点和10个输出节点全连接,正态分布标准差为1/192:
weight5 = variable_with_weight_loss(shape=[192, 10], stddev=1/192, wl=0.004)
bias5 = tf.Variable(tf.constant(0.0, shape=[10]))
# 这里没有加激励函数, softmax在计算loss的时候加
logits = tf.add(tf.matmul(local4, weight5), bias5)
计算loss与训练
定义loss的entropy和entropy_mean:
def loss(logits, labels):
labels = tf.cast(labels, tf.int64)
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits, labels=labels, name='cross_entropy_per_examples')
cross_entropy_mean = tf.reduce_mean(cross_entropy, name='cross_entropy')
tf.add_to_collection('losses', cross_entropy_mean)
return tf.add_n(tf.get_collection('losses'), name='total_loss')
得到真正的loss,并且拿Adam作为优化器:
real_loss = loss(logits, label_holder)
train_op = tf.train.AdamOptimizer(1e-3).minimize(real_loss)
得到分数最高的那一类准确率,默认是top1:
top_k_op = tf.nn.in_top_k(logits, label_holder, 1)
创建session来训练吧:
sess = tf.InteractiveSession()
tf.global_variables_initializer().run()
# 线程队列,16个线程来加速
tf.train.start_queue_runners()
for step in range(max_steps):
start_time = time.time()
image_batch, label_batch = sess.run([images_train, labels_train])
_, loss_value = sess.run([train_op, real_loss], feed_dict={image_holder:image_batch, label_holder:label_batch})
duration = time.time() - start_time
if step%10 == 0:
examples_per_sec = batch_size / duration
sec_per_batch = float(duration)
format_str = ('Step %d, loss = %.2f (%.1f examples/sec; %.3f sec/batch)')
print(format_str%(step, loss_value, examples_per_sec, sec_per_batch))
最后我们在测试集上进行测试看看, 打印准确率:
num_examples = 10000
import math
num_iter = int(math.ceil(num_examples / batch_size))
true_count = 0
total_sample_count = num_iter * batch_size
step = 0
while step < num_iter:
image_batch, label_batch = sess.run([images_test, labels_test])
predictions = sess.run([top_k_op], feed_dict={image_holder:image_batch, label_holder: label_batch})
true_count += np.sum(predictions)
step += 1
precision = true_count / total_sample_count
print('precision: ', precision)
ok,解决,运行一下看看吧,像我这种低配CPU,一跑就卡死…漫长的等待啊….可以看到最后结果其实并不是特别好。80%都没有。还用了2000多秒…
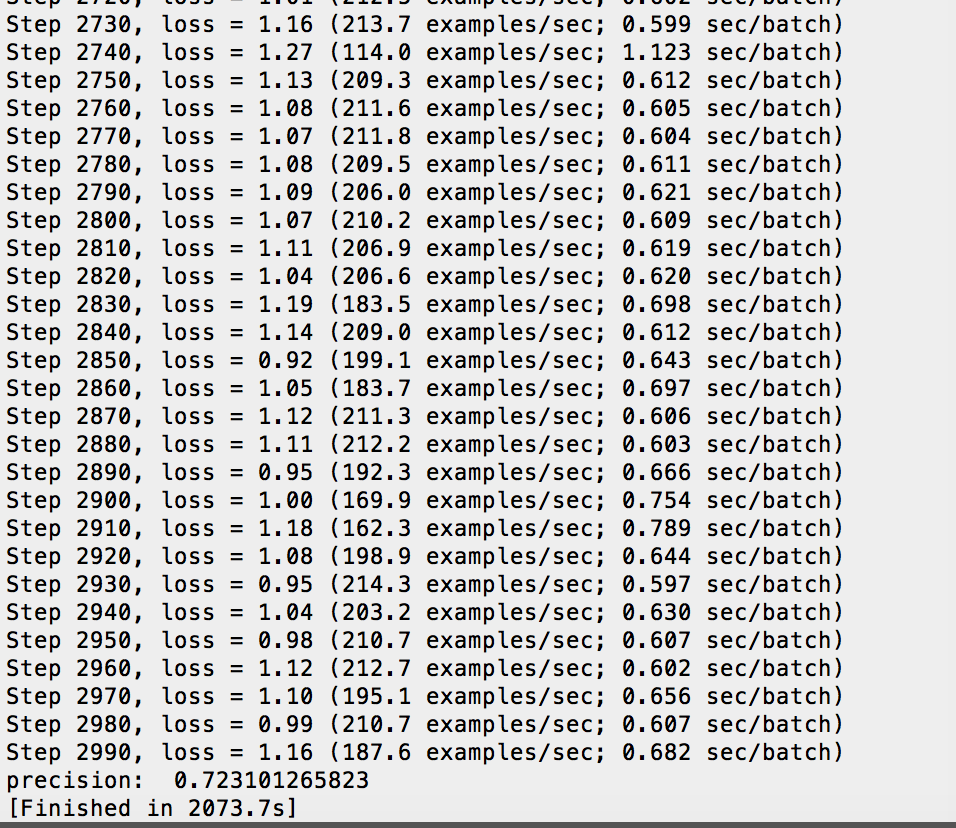
代码完全版
将上面两个cifar10的py文件,和我们的py文件放在一起,然后我们的py文件里所有的代码运行即可,数据集会自己下载:
import cifar10, cifar10_input
import tensorflow as tf
import numpy as np
import time
max_steps = 3000
batch_size = 128
data_dir = '/tmp/cifar10_data/cifar-10-batches-bin'
# Download and Extract
cifar10.maybe_download_and_extract()
images_train, labels_train = cifar10_input.distorted_inputs(data_dir, batch_size=batch_size)
images_test, labels_test = cifar10_input.inputs(eval_data=True, data_dir=data_dir, batch_size=batch_size)
image_holder = tf.placeholder(tf.float32, [batch_size, 24, 24, 3])
label_holder = tf.placeholder(tf.int32, [batch_size])
def variable_with_weight_loss(shape, stddev, wl):
var = tf.Variable(tf.truncated_normal(shape, stddev=stddev))
if wl is not None:
weight_loss = tf.multiply(tf.nn.l2_loss(var), wl, name='weight_loss')
tf.add_to_collection('losses', weight_loss)
return var
# 5*5*3的卷积核,64个,第一个卷积层不正则
weight1 = variable_with_weight_loss(shape=[5, 5, 3, 64], stddev=5e-2, wl=0.0)
# 卷积运算
kernel1 = tf.nn.conv2d(image_holder, weight1, [1, 1, 1, 1], padding="SAME")
# bias
bias1 = tf.Variable(tf.constant(0.0, shape=[64]))
# 第一层的表达式
conv1 = tf.nn.relu(tf.nn.bias_add(kernel1, bias1))
# 尺寸3*3,步长2*2最大池化进行池化,尺寸和步数不一样,增加数据丰富性
pool1 = tf.nn.max_pool(conv1, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1], padding="SAME")
# LRN对活跃的特征放大,不活跃的进行移植,增加模型泛化能力
norm1 = tf.nn.lrn(pool1, 4, bias=1.0, alpha=0.001/9.0, beta=0.75)
# 上一步提取了64个特征,现在输入5*5*64,不需要l2正则
weight2 = variable_with_weight_loss(shape=[5, 5, 64, 64], stddev=5e-2, wl=0.0)
kernel2 = tf.nn.conv2d(norm1, weight2, [1, 1, 1, 1], padding="SAME")
bias2 = tf.Variable(tf.constant(0.1, shape=[64]))
conv2 = tf.nn.relu(tf.nn.bias_add(kernel2, bias2))
norm2 = tf.nn.lrn(conv2, bias=1.0, alpha= 0.001/9.0, beta=0.75)
pool2 = tf.nn.max_pool(norm2, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1], padding='SAME')
# 这里要对pool2进行拉长成一个向量
reshape = tf.reshape(pool2, [batch_size, -1])
dim = reshape.get_shape()[1].value
# 全连接层特别容易过拟合!一定要加l2正则
weight3 = variable_with_weight_loss(shape=[dim,384], stddev=0.04, wl=0.004)
bias3 = tf.Variable(tf.constant(0.1, shape=[384]))
local3 = tf.nn.relu(tf.matmul(reshape, weight3) + bias3)
weight4 = variable_with_weight_loss(shape=[384, 192], stddev=0.04, wl=0.004)
bias4 = tf.Variable(tf.constant(0.1, shape=[192]))
local4 = tf.nn.relu(tf.matmul(local3, weight4) + bias4)
weight5 = variable_with_weight_loss(shape=[192, 10], stddev=1/192, wl=0.004)
bias5 = tf.Variable(tf.constant(0.0, shape=[10]))
# 这里没有加激励函数, softmax在计算loss的时候加
logits = tf.add(tf.matmul(local4, weight5), bias5)
def loss(logits, labels):
labels = tf.cast(labels, tf.int64)
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits, labels=labels, name='cross_entropy_per_examples')
cross_entropy_mean = tf.reduce_mean(cross_entropy, name='cross_entropy')
tf.add_to_collection('losses', cross_entropy_mean)
return tf.add_n(tf.get_collection('losses'), name='total_loss')
real_loss = loss(logits, label_holder)
train_op = tf.train.AdamOptimizer(1e-3).minimize(real_loss)
top_k_op = tf.nn.in_top_k(logits, label_holder, 1)
sess = tf.InteractiveSession()
tf.global_variables_initializer().run()
# 线程队列,16个线程来加速
tf.train.start_queue_runners()
for step in range(max_steps):
start_time = time.time()
image_batch, label_batch = sess.run([images_train, labels_train])
_, loss_value = sess.run([train_op, real_loss], feed_dict={image_holder:image_batch, label_holder:label_batch})
duration = time.time() - start_time
if step%10 == 0:
examples_per_sec = batch_size / duration
sec_per_batch = float(duration)
format_str = ('Step %d, loss = %.2f (%.1f examples/sec; %.3f sec/batch)')
print(format_str%(step, loss_value, examples_per_sec, sec_per_batch))
num_examples = 10000
import math
num_iter = int(math.ceil(num_examples / batch_size))
true_count = 0
total_sample_count = num_iter * batch_size
step = 0
while step < num_iter:
image_batch, label_batch = sess.run([images_test, labels_test])
predictions = sess.run([top_k_op], feed_dict={image_holder:image_batch, label_holder: label_batch})
true_count += np.sum(predictions)
step += 1
precision = true_count / total_sample_count
print('precision: ', precision)