我制作的工程代码在这:Tiny_Face_Recognition
论文地址:https://arxiv.org/abs/1801.07698
参考代码地址(使用的MXNet):https://github.com/deepinsight/insightface#512-d-feature-embedding
源码LResNet50E-IR网络结构代码:https://github.com/deepinsight/insightface/blob/master/src/symbols/fresnet.py
源码训练代码:https://github.com/deepinsight/insightface/blob/master/src/train_softmax.py
TF训练网络代码:https://github.com/auroua/InsightFace_TF/blob/master/nets/L_Resnet_E_IR.py
训练集:MS-Celeb-1M
验证集:LFW
运行环境与第三方库:
- Ubuntu 16.04 GPU: Tesla P40(24G)×1
- Python 3.5.0
- TensorFlow 1.10.0
- TensorLayer 1.11.0
- Opencv-python 3.4.3.18
- Dlib 19.15.0
- 网上流传的一份MS-Celeb-1M_clean_list.txt,清洗后的MS1M的图片索引,直接搜名字就可以搜到
- LFW官网上的pairs_test.txt与negtive_test.txt
注:预处理部分的验证集我没有使用MTCNN,使用的OpenCV+Dlib,对LFW进行了对齐,所以源代码下有一个lfw_faces的文件夹,为所有的人脸对齐后resize到112×112×3的图像,我没有给出,如果要完整走一遍我的流程的话请联系我,我单独把这部分发给你。
注:1.0版本工程代码:https://github.com/Ecohnoch/Voice-Image-Processing/tree/master/Face_Recognition/LResNet50E-IR
总结前三天的工作
前三天我们主要做了以下的工作:
- 了解了各种人脸分类相关的Loss函数,主要是ArcFace Loss
- 分析了作者的代码思路和相关细节
- 详细分析了ResNet50网络的构造和搭建方式
接下来包括今天还有四天的工作量,那么会放在哪里呢?我们来看一下我们离一个相对完整的高精度人脸识别全流程还有哪些事情没有做完:
- 预处理相关,原作者的人脸对齐使用的MTCNN,讲这个的论文我前几个就看了,其实感觉很简单
- 完整的能够跑的人脸识别代码没有写完,以及各种Debug
- 测试集和验证集上的评测
- 原论文的Ablation Study和Evaluation Results还没有详细的去读
所以今天的任务主要是预处理+可运行代码版本1.0的构造,当然在写这篇博文的时候,代码已经写完了
预处理相关
我理解的预处理可能和别人的预处理有些不一样,在人脸识别方面,我理解的预处理是从原始图像数据->一个Batch的全部流程叫做预处理。
那么在这个流程当中,涉及到了哪些工作?
下图是我个人理解的一个流程:
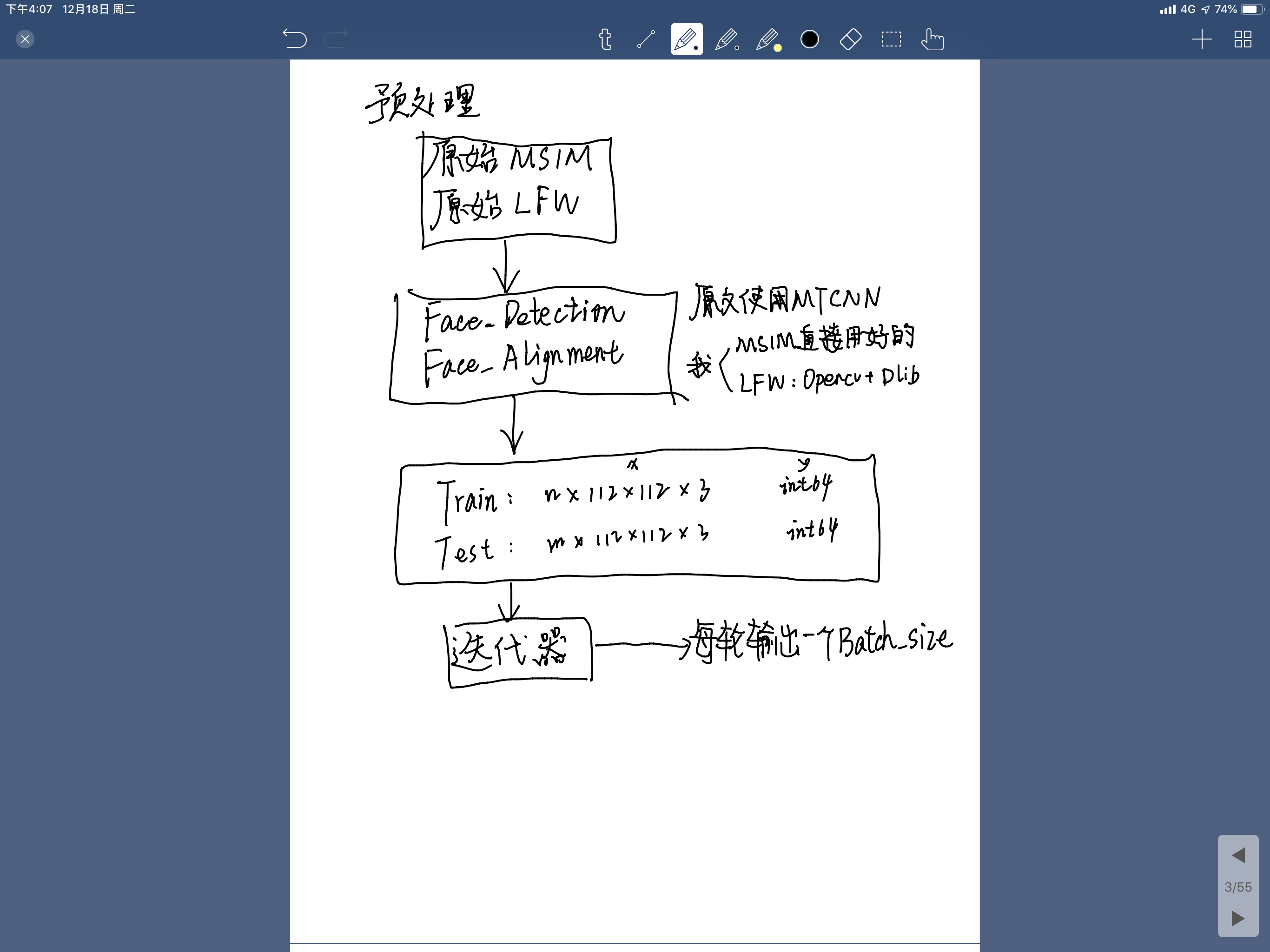
这个中间涉及到了一个非常复杂的活,那就是人脸检测和人脸对齐,这也是前几年伤透了大家脑筋的一个东西。
什么是人脸检测和人脸对齐?
人脸检测(Face Detection):从一张图片中检测是否有人脸
人脸对齐(Face Alignment):把人脸单独提取出来
原作者用的什么方法呢?他用的是MTCNN
MTCNN是什么?MTCNN是深圳先进技术研究院在2016年发表在ECCV中提出的一种包含人脸检测和人脸对齐的方法。
原论文地址:https://arxiv.org/abs/1604.02878
它的做法是用三个级联的CNN来实现的。
第一个通过去除边界,得到一系列的候选窗口
第二个通过人脸/非人脸的分类器,去除不包含人脸的候选窗口
第三个进行人脸的特征提取,来定位五个标志点。
具体的流程和过程他在这一页论文中已经讲得很详细了,上面是图示,下面的三个Stage分别表示三个CNN的作用:

具体一些的网络结构如下图所示:
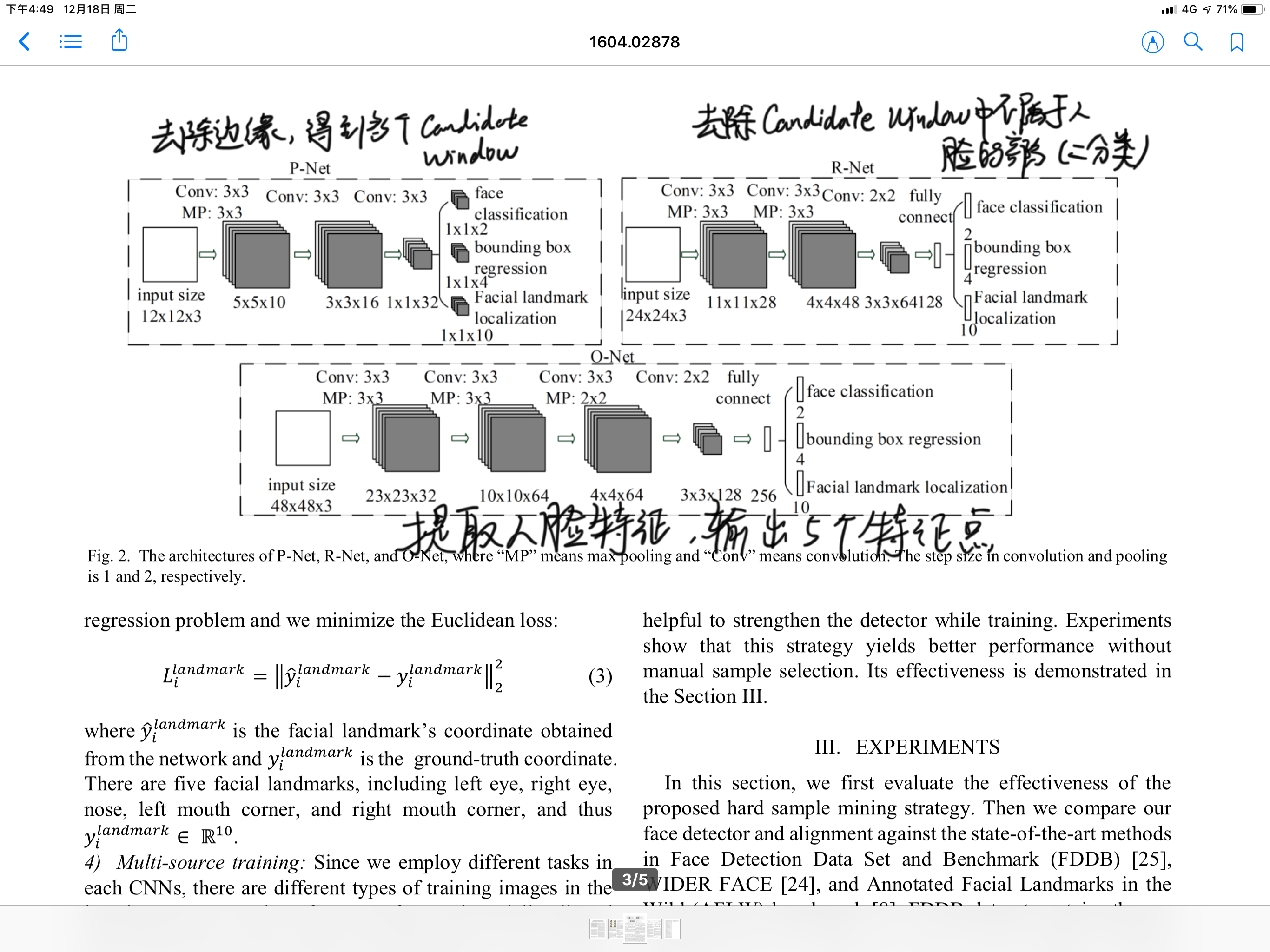
当然我的翻译和理解可能有一些问题,如果有错误的话可以联系我。
ArcFace原作者引用MTCNN后将人脸对齐后chop到了112×112×3, 再进行的之后的工作。
但我目前并没有使用这个操作,我的训练集是MS-Celeb-1M,是直接在官网山下载的已经对齐好的版本,我的验证集是LFW,由于图片比较小和少,我直接使用的Opencv+dlib的检测方法进行检测,操作大体如下:
- 导入Dlib的人脸检测器
- 遍历所有的图片,检测人脸,返回方形区域
- 用OpenCV截取方形区域,Resize到112×112×3,得到对齐图片
- OpenCV将对齐的图片写入新的文件夹中,结束
所以按照我的方法走整个流程的话,会缺失这部分的图像,需要的话可以联系我单独发给你,不发出公开的链接。
那么对齐之后,做整个的Train_set,并且迭代输出Batch的部分,这部分没有什么技术含量,抓住两个点就好了。
第一个点:Train_set的list中尽量放图片的路径,Batch中也尽量放图片的路径,然后再跑Batch的时候,临时调用函数将整个Batch中的路径变成【Batch_size×112×112×3】的形式,否则必然会内存爆炸。
第二个点:如何迭代的生成?首先整体的Train_set和label必然要经过Shuffle,迭代生成Batch可以定位start和end两个角标点,每轮的end=(start+batch_size)\%(Train_set的长度),当start<end的时候直接提出[start:end]部分即可,当start>end的时候提出[start:]+[:end]即可,每次提取后start都变为end即可。
网络结构
预处理做完后,就是网络结构设计,理论和参考代码部分均在前面三篇中,这里不过多介绍,直接上我画好的结构图:

这一整个是一个计算图,TensorFlow在运行的时候,会先搭建这样的一个计算图
然后开启一个会话sess,如果你想得到计算图中的某个结果,比如total_loss,你就需要sess.run(total_loss, feed_dict={x:输入, y:标签})
这都是非常基础的部分,不熟练的话要多走几个别的简单的流程就好了。
结构用代码的语言的话,大概就是这样:
if __name__ == '__main__':
os.environ['CUDA_VISIBLE_DEVICES'] = "0"
args = get_parser()
train_set, train_label = msm.get_train_set(args.dataset_dir, args.clean_list_path)
test_set_left, test_set_right, test_set_label = fe.get_test_set()
global_step = tf.Variable(name='global_step', initial_value=0, trainable=False)
inc_op = tf.assign_add(global_step, 1, name='increment_global_step')
x = tf.placeholder(tf.float32, [None, 112, 112, 3], name='x')
y = tf.placeholder(tf.int64, [None, ], name='label')
dropout_rate = tf.placeholder(name='dropout_rate', dtype=tf.float32)
w_init_method = tf.contrib.layers.xavier_initializer(uniform=False)
network = resnet.get_resnet(x, 50, type='ir', w_init=w_init_method, trainable=True, keep_rate=dropout_rate)
logit = resnet.arcface_loss(embedding=network.outputs, labels=y, w_init=w_init_method, out_num=args.num_output)
tl.layers.set_name_reuse(True)
test_net = resnet.get_resnet(x, 50, type='ir', w_init=w_init_method, trainable=False, reuse=True, keep_rate=dropout_rate)
embedding_tensor = test_net.outputs
inference_loss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logit, labels=y))
wd_loss = 0
for weights in tl.layers.get_variables_with_name('W_conv2d', True, True):
wd_loss += tf.contrib.layers.l2_regularizer(args.weight_decay)(weights)
for W in tl.layers.get_variables_with_name('resnet_v1_50/E_DenseLayer/W', True, True):
wd_loss += tf.contrib.layers.l2_regularizer(args.weight_decay)(W)
for weights in tl.layers.get_variables_with_name('embedding_weights', True, True):
wd_loss += tf.contrib.layers.l2_regularizer(args.weight_decay)(weights)
for gamma in tl.layers.get_variables_with_name('gamma', True, True):
wd_loss += tf.contrib.layers.l2_regularizer(args.weight_decay)(gamma)
# for beta in tl.layers.get_variables_with_name('beta', True, True):
# wd_loss += tf.contrib.layers.l2_regularizer(args.weight_deacy)(beta)
for alphas in tl.layers.get_variables_with_name('alphas', True, True):
wd_loss += tf.contrib.layers.l2_regularizer(args.weight_deacy)(alphas)
total_loss = inference_loss + wd_loss
p = int(512.0/args.batch_size)
lr_steps = [p*val for val in args.lr_steps]
lr = tf.train.piecewise_constant(global_step, boundaries=lr_steps, values=[0.001, 0.0005, 0.0003, 0.0001], name='lr_schedule')
opt = tf.train.MomentumOptimizer(learning_rate=lr, momentum=args.momentum)
grads = opt.compute_gradients(total_loss)
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops):
train_op = opt.apply_gradients(grads, global_step=global_step)
pred = tf.nn.softmax(logit)
acc = tf.reduce_mean(tf.cast(tf.equal(tf.argmax(pred, axis=1), y), dtype=tf.float32))
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
with tf.Session(config=config) as sess:
saver = tf.train.Saver(max_to_keep=args.saver_maxkeep)
sess.run(tf.global_variables_initializer())
idx = 0
count = 0
for i in range(args.epoch):
batch_train, batch_label, idx = get_train_batch(idx, args.batch_size, train_set, train_label)
start = time.time()
_, total_loss_val, inference_loss_val, wd_loss_val, _, acc_val = sess.run([train_op, total_loss, inference_loss, wd_loss, inc_op, acc], feed_dict={x: batch_train, y:batch_label, dropout_rate:0.4})
end = time.time()
pre_sec = args.batch_size / (end - start)
if count > 0 and count % args.show_info_interval == 0:
print('epoch %d, total_step %d, total loss %.2f, inference loss %.2f, training acc %.6f, time %.3f' % (i, count, total_loss_val, inference_loss_val, acc_val, pre_sec))
count += 1
# save ckpt files
if count > 0 and count % args.ckpt_interval == 0:
filename = 'InsightFace_iter_{:d}'.format(count) + '.ckpt'
filename = os.path.join(args.ckpt_path, filename)
saver.save(sess, filename)
工程代码地址
第一版本已经有能力完整跑完一遍数据集(85G图片),但还未进行验证检测,收敛的速度比较慢,待补充
地址:https://github.com/Ecohnoch/Voice-Image-Processing/tree/master/Face_Recognition/LResNet50E-IR