原创:岐山凤鸣,转载请注明本站域名
觉得不错不妨star/follow一下我的Github
Cifar-100心酸调参仓库:Ecohnoch:tensorflow-cifar100
寻找最佳学习率仓库:Ecohnoch:find best learning rate
Initialization初始化
DL界有一句名言: All you need is a bese init. If you can’t find the best init, try Batch Normalization.
当然这句话来自于2016年的ICLR论文 All you need is a best init
这篇论文提出了LSUV这种新的(在15年的时候算新的)CNN初始化方式,并且测试了CNN中不同的非线性激活和不同的初始化方式的结果,直观结果如下表:
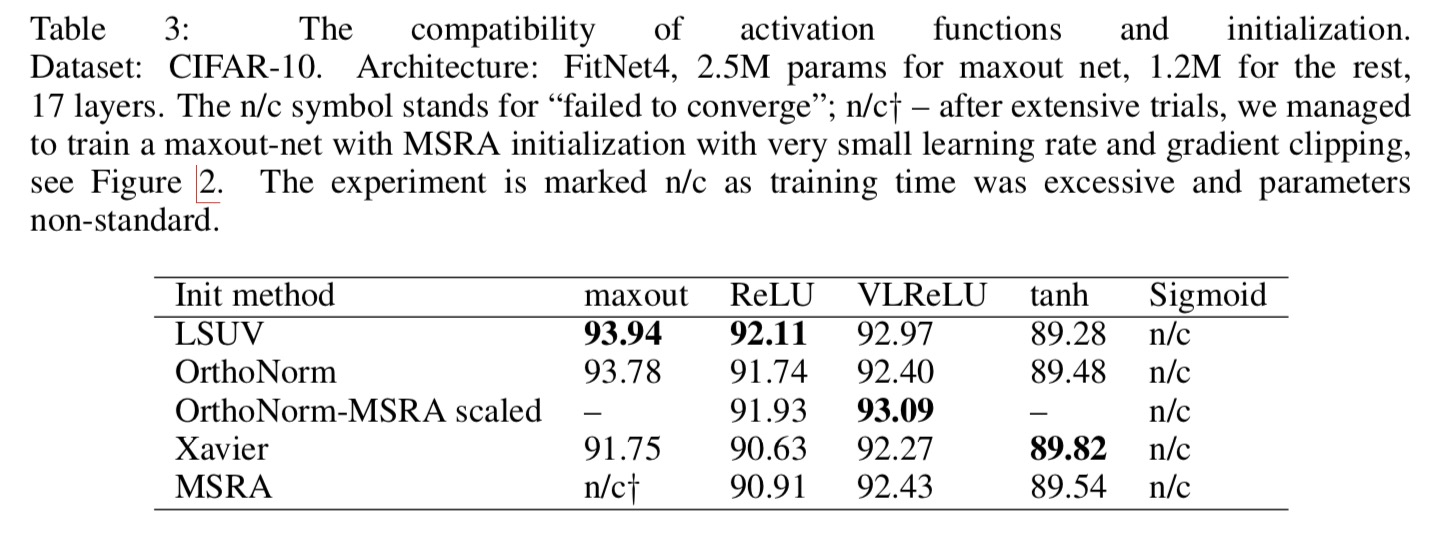
虽然加了BN后的测试来看并没有差距太多,不过网络权重初始化依然是非常重要的调参的一个环节。
下面我来介绍一下TensorFlow中的一些Init API,以及适用的场景。
常数项初始化
- tf.zeros_initializer()
- tf.ones_initializer()
适用场景一般都是bias,例如DenseLayer中初始化偏置为0这种。
正态分布初始化
- tf.random_normal_initializer()
- tf.truncated_normal_initializer()
前者为标准正态分布,后者为截断正态分布,意思也就是截取一段正态分布的分布,当生成的值大于两个标准偏差的值后会被丢弃重新绘制,非常常用,很多小CNN网络都会带截断正态分布的。一般还会带一个参数stddev=0.01或附近。
均匀分布初始化
- tf.random_uniform_initializer(minval=-10, maxval=10)
- tf.uniform_unit_scaling_initializer()
前者需要指定最大值和最小值,后者不需要
- tf.variance_scaling_initializer(scale=1.0, mode=’fan_in’, distribution=’normal)
这个mode可选fan_in、fan_out和fan_avg,控制计算标准差stddev
distribution为normal时是截断正态分布,uniform为均匀分布
默认情况下是截断正态分布
其他
- tf.orthogonal_initializer()
- tf.glorot_uniform_initializer()
- tf.glorot_normal_initializer()
- tf.contrib.layers.xavier_initializer()
第一个是正交矩阵随机数,在CNN中用的最多
第二个也称为Xavier uniform initializer, 均匀分布区间为[-sqrt(6 / (fan_in + fan_out)), + sqrt(6 / (fan_in + fan_out))],要注意!第二个和第四个是一个东西。
第三个的话是stddev = sqrt(2 / (fan_in + fan_out)) 的截断正态分布
测试分布形状的代码在我的研究神经网络初始化的Github仓库中: find_initializer
结果如下图所示,要注意glorot_normal_initializer和xavier_initializer是一个东西。
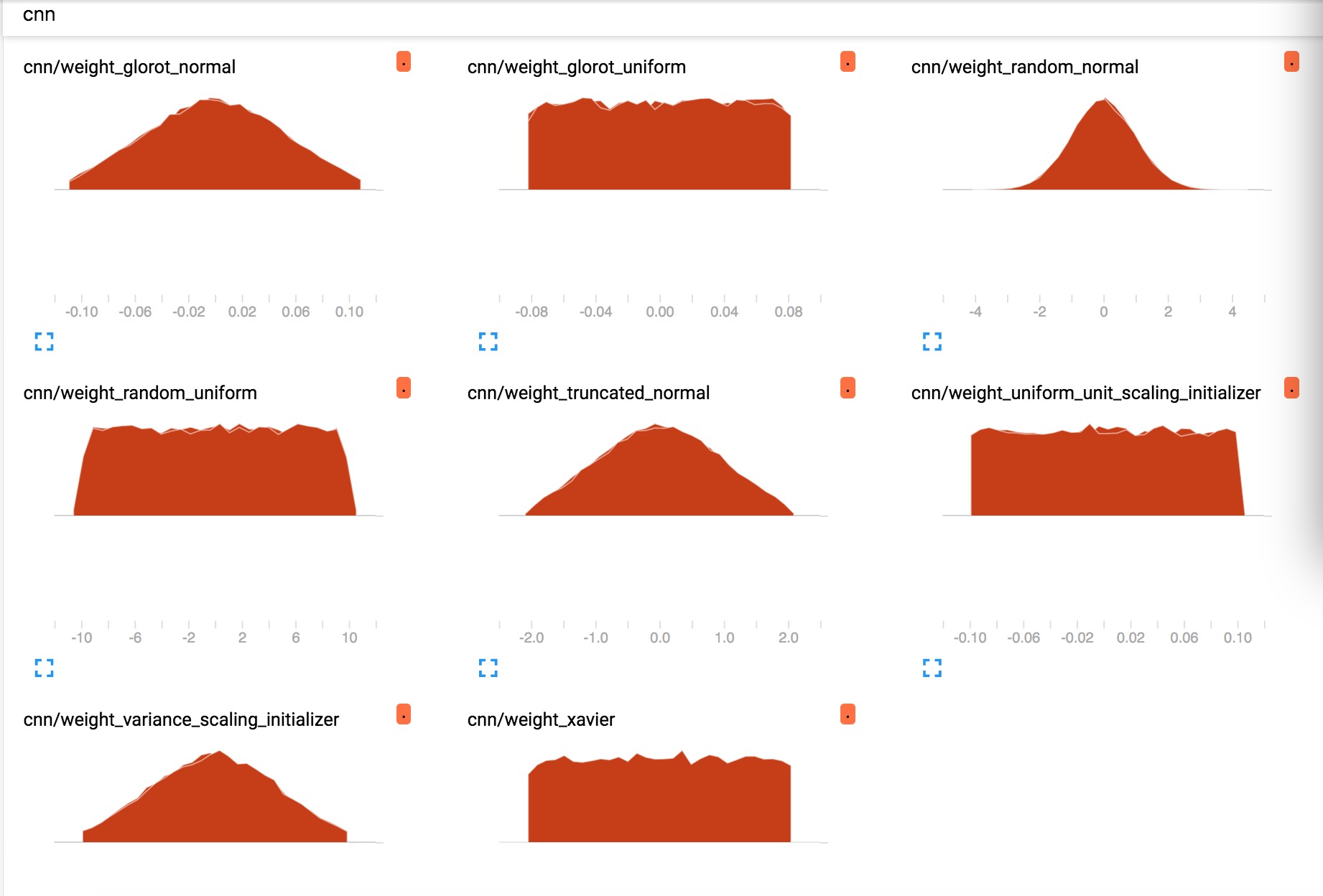
注意
需要注意的一点是,很多开发者有时候会告诉你无脑用xavier就可以了,不过在现在基本都是conv(no bias)-bn-relu的环境下,无脑xavier也许并不好,我是说不适用于这种情况,何凯明在调ResNet的时候,使用的he initializer,也就是msra初始化,很适用于上述这种结构,tf的写法即:
- tf.contrib.layers.variance_scaling_initializer(dtype=tf.float32)
具体关于Xavier和He 的数学推导即为何适用于各种结构,可以参考这篇文章
学习率衰减
学习率及相关超参数调整是非常麻烦而且能对结果造成很大影响的。
很多人说DL学到半途都是调参侠,虽然说调参侠听起来贬义,而且没学到什么东西,但这是非常重要且内容很深的一个过程。何凯明大大都在调参上弄过很长时间,并且不同调参技巧确实能够对模型性能提高,又为什么不去了解呢?就在最近两年,各大顶刊的调参论文也非常的多,甚至19年ICLR的best paper也与其相关,不过现代的很多网络调参都需要大量的GPU的支持,普通玩家一般只要掌握部分原理原则性的东西,多做点实验就可以了。
关于最初最佳的lr可以参考这篇论文Cyclical Learning Rates for Training Neural Networks,以及我在【人脸识别】和【MNIST】上用TensorFlow测试的代码仓库Find Best Learning Rate
目前广为接受的参数来自以下论文:
Regularizing Neural Networks by Penalizing Confident Output Distributions
这些参数也主要应用在cifar系列,imagenet系列上,有两种策略:
| batch_size | optimizer | lr-(epoch<60) | lr-(epoch<120) | lr-(epoch<160) | lr-(epoch<200) |
|---|---|---|---|---|---|
| 128 | Nesterov Momentum 0.9 | 0.1 | 0.02 | 0.004 | 0.0008 |
| batch_size | optimizer | lr-(epoch<150) | lr-(epoch<225) | lr-(epoch<300) |
|---|---|---|---|---|
| 128 | Nesterov Momentum 0.9 | 0.1 | 0.01 | 0.001 |
实际情况中,我个人的经验(不一定准确),在训练的时候,每100轮训练print上val loss,这样可以看看网络下没下降,要是到瓶颈了不下降,可以酌情将lr除以5或者10,然后跑十几个epoch后,继续降低lr,直到降到1e-6之后就差不多可以了,在达到瓶颈后降低lr,可以有效的提高测试acc。
下面说几个TensorFlow中的学习率衰减的方法:
方法一
手动调整,在模型训练时保存参数,训练到一定中途停掉,换学习率继续跑
方便指数 一颗星
危险指数 零颗星
方法二
将lr作为tf.placeholder(),然后每次sess在跑optimizer.minize或者apply_gradient的时候,把lr也手动带上,可以根据epoch进行调整。
方便指数 四颗星
危险指数 零颗星
参考方式如我的这个调参仓库的train里的lr_schedule写法:tensorflow-cifar100
方法三
使用tf自带的lr的API,有如下一些API:
- tf.train.piecewise_constant
- tf.train.inverse_time_decay
- tf.train.polynomial_decay
- tf.train.exponential_decay)
- tf.train.natural_exp_decay
- tf.train.cosine_decay
- tf.train.linear_cosine_decay
- tf.train.noisy_linear_cosine_decay
最上面那个就是梯度学习率,也就是global_step到了多少就计算多少次,我的人脸识别代码中就采用了这种技巧,可以看到代码中带有lr_steps和boundaries,即lr随着global_step的计算次数会更新为多少多少。
但也要注意,有时候会出现一些问题,如我在测试Cifar100时时长会出现各种学习率跳跃,原因不明,比较难操控。
不过也比较方便的说。
方便指数 四颗星
危险指数 三颗星
Warm Up
中文直译“热身”,即在网络最开始训练的时候采用小的learning rate,然后进行一段时间后,开始正常的lr schedule训练,大约能够提高1个多点的准确率,可以参考这个repo
这个非常简单,参考上述lr decay的三种方法,只要设置第一个epoch的lr很小,如0.001就可以了。
Label Smoothing
这是一种Regularization方法,假设原始的Ground Truth的分布为\(p_i\),那么进行Smoothing之后的分布为:
$p_i’ = p_i (1 - \epsilon) + \frac{\epsilon}{K} $
其中\(\epsilon\)是个很小的值,而K是类别,参考代码:label_smoothing
伪代码:
smooth_label(target, n_classes, epsilon):
one_hot_target = one_hot(target, n_classes, value=1-epsilon)
one_hot_target += epsilon / n_classes
return one_hot_target
具体work的原理就是防止过拟合,防止因为label不smothing(也就是分布和想象里的不一样)产生的误差,所以人为的对Ground Truth的值增加了一些正则内容,这样网络就不会【过于信任】我们给的label,从而降低拟合程度。
但实际效果也就能增加1-2个点左右,不过类似的研究有很多。
ECCV2018里一篇论文Pairwise Confusion for Fine-Grained Visual Classification是在Label Smoothing的思想上进行的扩展。通过在label中加入confusion,从而在细粒度分类里产生比较好的效果(也就多一两个点的效果…不过对每个类别来说在88%的情况下都多了两三个点,说明还是很awesome的
其他
- no bias decay
也就是只对Weights带L2正则,类似bias、BN的学习参数都不带。能够提高1-2个点。
- BN \(\gamma\)初始置0
BN是个好东西,一般都把它带上,然后gamma值初始设0,初始化的时候训练的更快
- FP16
用Float16代替原CNN中所有Float32的parameters,不能提高点,但可以大幅度提高速度…慎用。
- metric learning
这是下一篇要单独讲的,CNNs本质上提取了图像的特征,那么如何进行度量,例如相似度,如何操作,例如不同类的尽量分开,都需要在度量学习的基础上进行做文章。